
What a C programmer should know about memory

Source: Weapons by T4LLBERG, on Flickr (CC-BY-SA)
In 2007, Ulrich Drepper wrote a “What every programmer should know about memory“. Yes, it’s a wee long-winded, but it’s worth its salt. Many years and “every programmer should know about” articles later, the concept of virtual memory is still elusive to many, as if it was a kind of magic. Awww, I couldn’t resist the reference. Even the validity of the original article was questioned many years later. What gives?
“North bridge? What is this crap? That ain’t street-fighting.”
I’ll try to convey the practical side of things (i.e. what can you do) from “getting your fundamentals on a lock”, to more fun stuff. Think of it as a glue between the original article, and the things that you use every day. The examples are going to be C99 on Linux, but a lot of topics are universal. EDIT: I don’t have much knowledge about Windows, but I’d be thrilled to link an article which explains it. I tried my best to mention which functions are platform-specific, but again I’m only a human. If you find a discrepancy, please let me know.
Without further ado, grab a cup of coffee and let’s get to it.
Understanding virtual memory - the plot thickens
Unless you’re dealing with some embedded systems or kernel-space code, you’re going to be working in protected mode. This is awesome, since your program is guaranteed to have it’s own [virtual] address space. The word “virtual” is important here. This means, among other things, that you’re not bounded by the available memory, but also not entitled to any. In order to use this space, you have to ask the OS to back it with something real, this is called mapping. A backing can be either a physical memory (not necessarily RAM), or a persistent storage. The former is also called an “anonymous mapping”. But hold your horses.
The virtual memory allocator (VMA) may give you a memory it doesn’t have, all in a vain hope that you’re not going to use it. Just like banks today. This is called overcommiting, and while it has legitimate applications (sparse arrays), it also means that the memory allocation is not going to simply say “NO”.
char *block = malloc(1024 * sizeof(char));
if (block == NULL) {
return -ENOMEM; /* Sad :( */
}
The NULL return value checking is a good practice, but it’s not as powerful as it once was. With the overcommit, the OS may give your memory allocator a valid pointer to
memory, but if you’re going to access it - dang*. The dang in this case is platform-specific, but generally an OOM killer killing your process.
* — This is an oversimplification, as timbatron noted, and it’s further explained in the “Demand paging explained” section. But I’d like to go through the well-known stuff first before we delve into specifics.
Detour - a process memory layout
The layout of a process memory is well covered in the Anatomy of a Program in Memory by Gustavo Duarte, so I’m going to quote and reference to the original article, I hope it’s a fair use. I have only a few minor quibbles, for one it covers only a x86-32 memory layout, but fortunately nothing much has changed for x86-64. Except that a process can use much more space — the whopping 48 bits on Linux.
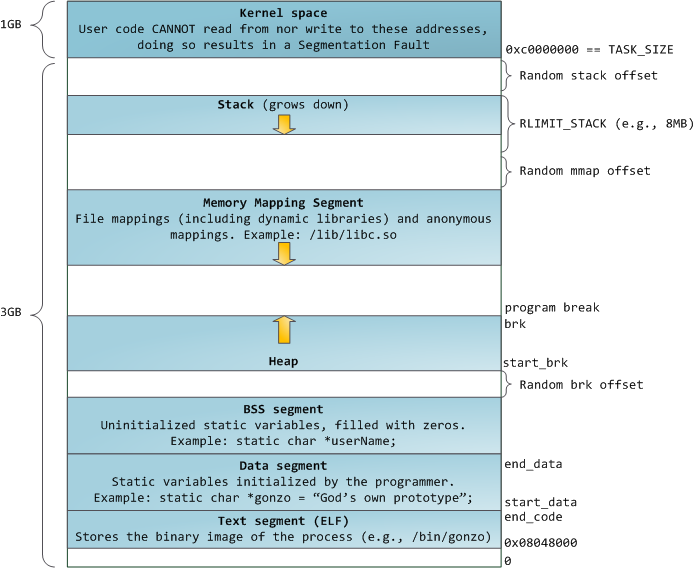
Source: Linux address space layout by Gustavo Duarte
It also shows the memory mapping segment (MMS) growing down, but that may not always be the case. The MMS usually starts (x86/mm/mmap.c:113 and arch/mm/mmap.c:1953) at a randomized address just below the lowest address of the stack. Usually, because it may start above the stack and grow upwards iff the stack limit is large (or unlimited), or the compatibility layout is enabled. How is this important? It’s not, but it helps to give you an idea about the free address ranges.
Looking at the diagram, you can see three possible variable placements: the process data segment (static storage or heap allocation), the memory mapping segment, and the stack. Let’s start with that one.
Understanding stack allocation
Utility belt:
alloca()- allocate memory in the stack frame of the callergetrlimit()- get/set resource limitssigaltstack()- set and/or get signal stack context
The stack is kind of easy to digest, everybody knows how to make a variable on the stack right? Here are two:
int stairway = 2;
int heaven[] = { 6, 5, 4 };
The validity of the variables is limited by scope. In C, that means this: {}. So each time a closing curly bracket comes, a variable dies.
And then there’s alloca(), which allocates memory dynamically in the current stack frame. A stack frame is not (entirely) the same thing as memory frame (aka physical page), it’s simply a group of data that gets pushed onto the stack (function, parameters, variables…). Since we’re on the top of the stack, we can use the remaining memory up to the stack size limit.
This is how variable-length arrays (VLA), and also alloca() work, with one difference - VLA validity is limited by the scope, alloca’d memory persists until the current function returns (or unwinds if you’re feeling sophisticated). This is no language lawyering, but a real issue if you’re using the alloca inside a loop, as you don’t have any means to free it.
void laugh(void) {
for (unsigned i = 0; i < megatron; ++i) {
char *res = alloca(2);
memcpy(res, "ha", 2);
char vla[2] = {'h','a'}
} /* vla dies, res lives */
} /* all allocas die */
Neither VLA or alloca play nice with large allocations, because you have almost no control over the available stack memory and the allocation past the stack limits leads to the jolly stack overflow. There are two ways around it, but neither is practical.
The first idea is to use a sigaltstack() to catch and handle the SIGSEGV. However this just lets you catch the stack overflow.
The other way is to compile with split-stacks. It’s called this way, because it really splits the monolithic stack into a linked-list of smaller stacks called
stacklets. As far as I know, GCC and clang support it with the -fsplit-stack option.
In theory this also improves memory consumption and reduces the cost of creating threads — because the stack can start really small and grow on demand.
In reality, expect compatibility issues, as it needs a split-stack aware linker (i.e. gold) to play nice with the split-stack unaware libraries,
and performance issues (the “hot split” problem in Go is nicely explained by Agis Anastasopoulos).
Understanding heap allocation
Utility belt:
The heap allocation can be as simple as moving a program break and claiming the memory between the old position, and the new position.
Up to this point, a heap allocation is as fast as stack allocation (sans the paging, presuming the stack is already locked in memory). But there’s a cat, I mean catch, dammit.
char *block = sbrk(1024 * sizeof(char));
⑴ we can’t reclaim unused memory blocks, ⑵ is not thread-safe since the heap is shared between threads, ⑶ the interface is hardly portable, libraries must not touch the break
man 3 sbrk— Various systems use various types for the argument of sbrk(). Common are int, ssize_t, ptrdiff_t, intptr_t.
For these reasons libc implements a centralized interface for memory allocation. The implementation varies, but it provides you a thread safe memory allocation of any size … at a cost. The cost is latency, as there is now locking involved, data structures keeping the information about used / free blocks and an extra memory overhead. The heap is not used exclusively either, as the memory mapping segment is often utilised for large blocks as well.
man 3 malloc— Normally,malloc()allocates memory from the heap, … when allocating blocks of memory larger than MMAP_THRESHOLD, the glibcmalloc()implementation allocates the memory as a private anonymous mapping.
As the heap is always contiguous from start_brk to brk, you can’t exactly punch holes through it and reduce the data segment size. Imagine the following scenario:
char *truck = malloc(1024 * 1024 * sizeof(char));
char *bike = malloc(sizeof(char));
free(truck);
The heap [allocator] moves the brk to make space for truck. The same for the bike. But after the truck is freed, the brk can’t be moved down, as it’s the bike that occupies the highest address. The result is that your process can reuse the former truck memory, but it can’t be returned to the system until the bike is freed.
But presuming the truck was mmaped, it wouldn’t reside in the heap segment, and couldn’t affect the program break.
Still, this trick doesn’t prevent the holes created by small allocations (in another words “cause fragmentation”).
Note that the free() doesn’t always try to shrink the data segment, as that is a potentially expensive operation.
This is a problem for long-running programs, such as daemons. A GNU extension, called malloc_trim(), exists for releasing memory from the top of the heap, but it can be painfully slow. It hurts real bad for a lot of small objects, so it should be used sparingly.
When to bother with a custom allocator
There are a few practical use cases where a GP allocator falls short — for example an allocation of a large number of small fixed-size chunks. This might not look like a typical pattern, but it is very frequent. For example, lookup data structures like trees and tries typically require nodes to build hierarchy. In this case, not only the fragmentation is the problem, but also the data locality. A cache-efficient data structure packs the keys together (preferably on the same page), instead of mixing it with data. With the default allocator, there is no guarantee about the locality of the blocks from the subsequent allocations. Even worse is the space overhead for allocating small units. Here comes the solution!

Source: Slab by wadem, on Flickr (CC-BY-SA)
Slab allocator
Utility belt:
The principle of slab allocation was described by Bonwick for a kernel object cache, but it applies for the user-space as well. Oh-kay, we’re not interested in pinning slabs to CPUs, but back to the gist — you ask the allocator for a slab of memory, let’s say a whole page, and you cut it into many fixed-size pieces. Presuming each piece can hold at least a pointer or an integer, you can link them into a list, where the list head points to the first free element.
/* Super-simple slab. */
struct slab {
void **head;
};
/* Create page-aligned slab */
struct slab *slab = NULL;
posix_memalign(&slab, page_size, page_size);
slab->head = (void **)((char*)slab + sizeof(struct slab));
/* Create a NULL-terminated slab freelist */
char* item = (char*)slab->head;
for(unsigned i = 0; i < item_count; ++i) {
*((void**)item) = item + item_size;
item += item_size;
}
*((void**)item) = NULL;
Allocation is then as simple as popping a list head. Freeing is equal to as pushing a new list head.
There is also a neat trick. If the slab is aligned to the page_size boundary, you can get the slab pointer as cheaply
as rounding down to the page_size.
/* Free an element */
struct slab *slab = (void *)((size_t)ptr & PAGESIZE_BITS);
*((void**)ptr) = (void*)slab->head;
slab->head = (void**)ptr;
/* Allocate an element */
if((item = slab->head)) {
slab->head = (void**)*item;
} else {
/* No elements left. */
}
Great, but what about binning, variable size storage, cache aliasing and caffeine, …? Peek at my old implementation for Knot DNS to get the idea, or use a library that implements it. For example, *gasp*, the glib implementation has a tidy documentation and calls it “memory slices”.
Memory pools
Utility belt:
As with the slab, you’re going to outsmart the GP allocator by asking it for whole chunks of memory only. Then you just slice the cake until it runs out, and then ask for a new one. And another one. When you’re done with the cakes, you call it a day and free everything in one go.
Does it sound obvious and stupid simple? Because it is, but that’s what makes it great for specific use cases. You don’t have to worry about synchronisation, not about freeing either. There are no use-after-free bugs, data locality is much more predictable, there is almost zero overhead for small fragments.
The pattern is surprisingly suitable for many tasks, ranging from short-lived repetitive (i.e. “network request processing”), to long-lived immutable data (i.e. “frozen set”). You don’t have to free everything either. If you can make an educated guess on how much memory is needed on average, you can just free the excess memory and reuse. This reduces the memory allocation problem to simple pointer arithmetic.
And you’re in luck here, as the GNU libc provides, *whoa*, an actual API for this. It’s called obstacks, as in “stack of objects”. The HTML documentation formatting is a bit underwhelming, but minor quibbles aside — it allows you to do both pool allocation, and full or partial unwinding.
/* Define block allocator. */
#define obstack_chunk_alloc malloc
#define obstack_chunk_free free
/* Initialize obstack and allocate a bunch of animals. */
struct obstack animal_stack;
obstack_init (&animal_stack);
char *bob = obstack_alloc(&animal_stack, sizeof(animal));
char *fred = obstack_alloc(&animal_stack, sizeof(animal));
char *roger = obstack_alloc(&animal_stack, sizeof(animal));
/* Free everything after fred (i.e. fred and roger). */
obstack_free(&animal_stack, fred);
/* Free everything. */
obstack_free(&animal_stack, NULL);
There is one more trick to it, you can grow the object on the top of the stack. Think buffering input, variable-length arrays,
or just a way to combat the realloc()-strcpy() pattern.
/* This is wrong, I better cancel it. */
obstack_grow(&animal_stack, "long", 4);
obstack_grow(&animal_stack, "fred", 5);
obstack_free (&animal_stack, obstack_finish(&animal_stack));
/* This time for real. */
obstack_grow(&animal_stack, "long", 4);
obstack_grow(&animal_stack, "bob", 4);
char *result = obstack_finish(&animal_stack);
printf("%s\n", result); /* "longbob" */
Demand paging explained
Utility belt:
One of the reasons why the GP memory allocator doesn’t immediately return the memory to the system is, that it’s costly.
The system has to do two things: ⑴ establish the mapping of a virtual page to real page, and ⑵ give you a blanked real page.
The real page is called frame, now you know the difference. Each frame must be sanitized, because you don’t want the operating system to leak your secrets to another process, would you?
But here’s the trick, remember the overcommit? The virtual memory allocator honours the only the first part of the deal,
and then plays some “now you see me and now you don’t” shit — instead of pointing you to a real page, it points to a special page 0.
Each time you try to access the special page, a page fault occurs, which means that: the kernel pauses process execution and fetches a real page, then it updates the page tables, and resumes like nothing happened. That’s about the best explanation I could muster in one sentence, here’s more detailed one. This is also called “demand paging” or “lazy loading”.
The Spock said that “one man cannot summon the future”, but here you can pull the strings.
The memory manager is no oracle and it makes very conservative predictions about how you’re going to access memory, but you may know better. You can lock the contiguous memory block in physical memory, avoiding further page faulting:
char *block = malloc(1024 * sizeof(char));
mlock(block, 1024 * sizeof(char));
*psst*, you can also give an advise about your memory usage pattern:
char *block = malloc(1024 * sizeof(block));
madvise(block, 1024 * sizeof(block), MADV_SEQUENTIAL);
The interpretation of the actual advice is platform-specific, the system may even choose to ignore it altogether, but most of the platforms play nice.
Not all advices are well-supported, and some even change semantics (MADV_FREE drops dirty private memory), but the MADV_SEQUENTIAL, MADV_WILLNEED, and MADV_DONTNEED holy trinity is what you’re going to use most.
Fun with flags memory mapping
Utility belt:
sysconf()- get configuration information at run timemmap()- map virtual memorymincore()- determine whether pages are resident in memoryshmat()- shared memory operations
There are several things that the memory allocator just can’t do, memory maps to to rescue!
To pick one, the fact that you can’t choose the allocated address range.
For that we’re willing to sacrifice some comfort — we’re going to be working with whole pages from now on.
Just to make things clear, a page is usually a 4K block, but you shouldn’t rely on it and use sysconf() to discover it.
long page_size = sysconf(_SC_PAGESIZE); /* Slice and dice. */
Side note — even if the platform advertises a uniform page size, it may not do so in the background. For example a Linux has a concept of transparent huge pages (THP) to reduce the cost of address translation and page faulting for contiguous blocks. This is however questionable, as the huge contiguous blocks become scarce when the physical memory gets fragmented. The cost of faulting a huge page also increases with the page size, so it’s not very efficient for “small random I/O” workload. This is unfortunately transparent to you, but there is a Linux-specific mmap option MAP_HUGETLB that allows you to use it explicitly, so you should be aware of the costs.
Fixed memory mappings
Say you want to do fixed mapping for a poor man’s IPC for example, how do you choose an address? On x86-32 bit it’s a risky proposal, but on the 64-bit, an address around 2/3rds of the TASK_SIZE (highest usable address of the user space process) is a safe bet. You can get away without fixed mapping, but then forget pointers in your shared memory.
#define TASK_SIZE 0x800000000000
#define SHARED_BLOCK (void *)(2 * TASK_SIZE / 3)
void *shared_cats = shmat(shm_key, SHARED_BLOCK, 0);
if(shared_cats == (void *)-1) {
perror("shmat"); /* Sad :( */
}
Okay, I get it, this is hardly a portable example, but you get the gist. Mapping a fixed address range is usually considered unsafe at least, as it doesn’t check whether there is something already mapped or not. There is a mincore() function to tell you whether a page is mapped or not, but you’re out of luck in multi-threaded environment.
However, fixed-address mapping is not only useful for unused address ranges, but for the used address ranges as well.
Remember how the memory allocator used mmap() for bigger chunks? This makes efficient sparse arrays possible thanks to the on-demand paging. Let’s say you have created a sparse array, and now you want to free some data, but how to do that? You can’t exactly free() it, and munmap() would render it unusable. You could use the madvise() MADV_FREE / MADV_DONTNEED to mark the pages free, this is the best solution performance-wise as the pages don’t have to be faulted in, but the semantics of the advice differs is implementation-specific.
A portable approach is to map over the sucker.
void *array = mmap(NULL, length, PROT_READ|PROT_WRITE,
MAP_ANONYMOUS, -1, 0);
/* ... some magic gone awry ... */
/* Let's clear some pages. */
mmap(array + offset, length, MAP_FIXED|MAP_ANONYMOUS, -1, 0);
This is equivalent to unmapping the old pages and mapping them again to that special page. How does this affect the perception of the process memory consumption — the process still uses the same amount of virtual memory, but the resident [in physical memory] size lowers. This is as close to memory hole punching as we can get.
File-backed memory maps
Utility belt:
msync()- synchronize a file with memory mapftruncate()- truncate a file to a specified lengthvmsplice()- splice user pages into a pipe
So far we’ve been all about anonymous memory, but it’s the file-backed memory mapping that really shines in the 64 bit address space, as it provides you with intelligent caching, synchronization and copy-on-write. Maybe that’s too much.
To most people, LMDB is magic performance sprinkles compared to using the filesystem directly. ;)
— Baby_Food on r/programming
The file-backed shared memory maps add novel mode MAP_SHARED, which means that the changes you make to the pages will be written back to the file, therefore shared with other processes.
The decision of when to synchronize is left up to the memory manager, but fortunately there’s a msync() function to enforce the synchronization with the backing store.
This is great for the databases, as it guarantees durability of the written data. But not everyone needs that, it’s perfectly okay not to sync if the durability isn’t required, you’re not going to lose write visibility. This is thanks to the page cache, and it’s good because you can use memory maps for cheap IPC for example.
/* Map the contents of a file into memory (shared). */
int fd = open(...);
void *db = mmap(NULL, file_size, PROT_READ|PROT_WRITE,
MAP_SHARED, fd, 0);
if (db == (void *)-1) {
/* Mapping failed */
}
/* Write to a page */
char *page = (char *)db;
strcpy(page, "bob");
/* This is going to be a durable page. */
msync(page, 4, MS_SYNC);
/* This is going to be a less durable page. */
page = page + PAGE_SIZE;
strcpy(page, "fred");
msync(page, 5, MS_ASYNC);
Note that you can’t map more bytes than the file actually has, so you can’t grow it or shrink it this way. You can however create (or grow) a sparse file in advance with ftruncate(). The downside is, that it makes compaction harder, as the ability to punch holes through a sparse file depends both on the file system, and the platform.
The fallocate(FALLOC_FL_PUNCH_HOLE) on Linux is your best chance, but the most portable (and easiest) way is to make a copy of the file without the trimmed stuff.
/* Resize the file. */
int fd = open(...);
ftruncate(fd, expected_length);
Accessing a file memory map doesn’t exclude using it as a file either. This is useful for implementing a split access, where you map the file read only, but write to the file using a standard file API. This is good for security (as the exposed map is write-protected), but there’s more to it. The msync() implementation is not defined, so the MS_SYNC may very well be just a sequence of synchronous writes. Yuck. In that case, it may be faster to use a regular file APIs to do an asynchronous pwrite() and fsync() / fdatasync() for synchronisation or cache invalidation.
As always there is a caveat — the system has to have a unified buffer cache. Historically, a page cache and block device cache (raw blocks) were two different things. This means that writing to a file using a standard API and reading it through a memory map is not coherent1, unless you invalidate buffers after each write. Uh oh. On the other hand, you’re in luck unless you’re running OpenBSD or Linux < 2.4.
Copy-on-write
So far this was about shared memory mapping. But you can use the memory mapping in another way — to map a shared copy of a file, and make modifications without modifying the backing store. Note that the pages are not duplicated immediately, that wouldn’t make sense, but in the moment you modify them. This is not only useful for forking processes or loading shared libraries, but also for working on a large set of data in-place, from multiple processes at once.
int fd = open(...);
/* Copy-on-write mapping */
void *db = mmap(NULL, file_size, PROT_READ|PROT_WRITE,
MAP_PRIVATE, fd, 0);
if (db == (void *)-1) {
/* Mapping failed */
}
/* This page will be copied as soon as we write to it */
char *page = (char *)db;
strcpy(page, "bob");
Zero-copy streaming
Since the file is essentially a memory, you can stream it to pipes (that includes sockets), zero-copy style. Unlike the splice(), this plays well with the copy-on-write modification of the data. Disclaimer: This is for Linux folks only!
int sock = get_client();
struct iovec iov = { .iov_base = cat_db, .iov_len = PAGE_SIZE };
int ret = vmsplice(sock, &iov, 1, 0);
if (ret != 0) {
/* No streaming :( */
}
When mmap() isn’t the holy grail
There are pathological cases where mmapping a file is going to be much worse than the usual approach. A rule of thumb is that handling a page fault is slower than simply reading a file block, on the basis that it has to read the file block and do something more. In reality though, mmapped I/O may be faster as it avoids double or triple caching of the data, and does read-ahead in the background. But there are times when this is going to hurt. One such example is “small random reads in a file larger than available memory”. In this case the system reads ahead blocks that are likely not to be used, and each access is going to page fault instead. You can combat this to a degree with madvise().
Then there’s TLB thrashing. Translation of each virtual page to a frame is hardware-assisted, and the CPU keeps a cache of latest translations — this is the Translation Lookaside Buffer. A random access to a larger number of pages than the cache can hold inevitably leads to “thrashing”, as the system has to do the translation by walking the page tables. For other cases, the solution is to use huge pages, but it’s not going to cut it, as loading megabytes worth of data just to access a few odd bytes has even more detrimental effect.
Understanding memory consumption
Utility belt:
The concept of shared memory renders the traditional approach — measuring resident size &mdash obsolete, as there’s no just quantification on the amount exclusive for your process. That leads to confusion and horror, which can be two-fold:
With mmap’d I/O, our app now uses almost zero memory.
— CorporateGuyHelpz! My process writing to shared map leaks so much memory!!1
— HeavyLifter666
There are two states of pages, clean and dirty. The difference is that a dirty page has to be flushed to permanent storage before
it can be reclaimed. The MADV_FREE advice uses this as a cheap way to free memory just by clearing the dirty bit instead of updating the page
table entry. In addition, each page can be either private or shared, and this is where things get confusing.
Both claims are [sort of] true, depending on the perspective. Do pages in the buffer cache count towards the process memory consumption? What about when a process dirties file-backed pages that end up in the buffer cache? How to make something out of this madness?
Imagine a process, the_eye, writing to the shared map of mordor. Writing to the shared memory doesn’t count towards Rss, right?
$ ps -p $$ -o pid,rss
PID RSS
17906 1574944 # <-- WTF?
Err, back to the drawing board.
PSS (Proportional Set Size)
Proportional Set Size counts the private maps and adds a portion of the shared maps. This is as fair as we can get when talking about memory. By “portion”, I mean a size of a shared map, divided by the number of processes sharing it. Let’s see an example, we have an application that does read/write to a shared memory map.
$ cat /proc/$$/maps
00400000-00410000 r-xp 0000 08:03 1442958 /tmp/the_eye
00bda000-01a3a000 rw-p 0000 00:00 0 [heap]
7efd09d68000-7f0509d68000 rw-s 0000 08:03 4065561 /tmp/mordor.map
7f0509f69000-7f050a108000 r-xp 0000 08:03 2490410 libc-2.19.so
7fffdc9df000-7fffdca00000 rw-p 0000 00:00 0 [stack]
... snip ...
Here’s the simplified breakdown of each map, the first column is the address range, the second is permissions information, where r stands for read, w stands for write, x means executable — so far the classic stuff — s is shared and p is private. Then there’s offset, device, inode, and finally a pathname.
Here’s the documentation, massively comprehensive.
I admit I’ve snipped the not-so-interesting bits from the output. Read FAQ (Why is “strict overcommit” a dumb idea?) if you’re interested why the shared libraries are mapped as private, but it’s the map of mordor that interests us:
$ grep -A12 mordor.map /proc/$$/smaps
Size: 33554432 kB
Rss: 1557632 kB
Pss: 1557632 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 1557632 kB
Private_Dirty: 0 kB
Referenced: 1557632 kB
Anonymous: 0 kB
AnonHugePages: 0 kB
Swap: 0 kB
KernelPageSize: 4 kB
MMUPageSize: 4 kB
Locked: 0 kB
VmFlags: rd wr sh mr mw me ms sd
Private pages on a shared map — what am I, a wizard? On Linux, even a shared memory is counted as private unless it’s actually shared. Let’s see if it’s in the buffer cache:
# Seems like the first part is...
$ vmtouch -m 64G -v mordor.map
[OOo ] 389440/8388608
Files: 1
Directories: 0
Resident Pages: 389440/8388608 1G/32G 4.64%
Elapsed: 0.27624 seconds
# Let's load it in the cache!
$ cat mordor.map > /dev/null
$ vmtouch -m 64G -v mordor.map
[ooooooooooooooooooooooooo oooOOOOOOO] 2919606/8388608
Files: 1
Directories: 0
Resident Pages: 2919606/8388608 11G/32G 34.8%
Elapsed: 0.59845 seconds
Whoa, simply reading a file gets it cached? Anyway, how’s our process?
ps -p $$ -o pid,rss
PID RSS
17906 286584 # <-- Wait a bloody minute
A common misconception is that mapping a file consumes memory, whereas reading it using file API does not. One way or another, the pages from that file are going to get in the buffer cache. There is only a small difference, a process has to create the page table entries with mmap way, but the pages themselves are shared. Interestingly our process Rss shrinked, as there was a demand for the process pages.
Sometimes all of our thoughts are misgiven
The file-backed memory is always reclaimable, the only difference between dirty and clean — the dirty memory has to be cleaned before it can be reclaimed. So should you panick when a process consumes a lot of memory in top?
Start panicking (mildly) when a process has a lot of anonymous dirty pages — these can’t be reclaimed. If you see a very large growing anonymous mapping segment, you’re probably in trouble (and make it double). But the Rss or even Pss is not to be blindly trusted.
Another common mistake is to assume any relation between the process virtual memory and the memory consumption, or even treating all memory maps equally. Any reclaimable memory, is as good as a free one. To put it simply, it’s not going to fail your next memory allocation, but it may increase latency — let me explain.
The memory manager is making hard choices about what to keep in the physical memory, and what not. It may decide to page out a part of the process memory to swap in favour of more space for buffers, so the process has to page in that part on the next access.
Fortunately it’s usually configurable. For example, there is an option called swappiness on Linux, that determines when should the kernel start
paging out anonymous memory. A value of 0 means “until abso-fucking-lutely necessary”.
An end, once and for all
If you got here, I salute you! I started this article as a break from actual work, in a hope that simply explaining a thousand times explained concepts in a more accessible way is going to help me to organize thoughts, and help others in the process. It took me longer than expected. Way more.
I have nothing but utmost respect for writers, as it’s a tedious hair-pulling process of neverending edits and rewrites. Somewhere, Jeff Atwood has said that the best book about learning how to code is the one about building houses. I can’t remember where it was, so I can’t quote it. I could only add, that book about writing comes next. After all, that’s programming in it’s distilled form — writing stories, clear an concise.
EDIT: I’ve fixed the stupid mistakes with alloca() and sizeof(char *) vs sizeof(char), thanks immibis and BonzaiThePenguin. Thanks sWvich for pointing out missing cast in slab + sizeof(struct slab). Obviously I should have run the article through static analysis, but I didn’t — lesson learned.
Open question — is there anything better than Markdown code block, where I could show an annotated excerpt with a possibility to download the whole code block?
-
A fancy way to say you’re going to get different data. ↩